

AI破壁·科研小白的临床数据分析实战指南 第02篇
一个做II期临床的研究者曾发给我一张截图——EDC系统导出的原始数据,
打开是密密麻麻的列:USUBJID、VISITNUM、LBTEST、LBSTRESN……
他问我:"这里哪个是血糖?"
这个问题,几乎是所有临床研究者第一次面对真实数据时的真实反应。 数据不是你想象中那张填好的Excel表。 它是一套有自己语法、结构和"方言"的系统——你不先读懂它,根本谈不上分析它。
大多数人以为临床试验数据就是CRF表的电子版:一行一个受试者,一列一个指标。 但真实的情况是:你的数据横跨至少四个来源,分散在完全不同的结构里。
EDC系统是主力,存放了大部分临床观测数据,但它按"访视×域"组织,不是按"受试者×指标"展开的。 实验室检测结果通常以CSV单独下发,和EDC数据的字段命名规则完全不同。 SAE(严重不良事件)报告多是PDF或Word格式的叙述性文本,需要手工提取结构化信息。 稽查轨迹(Audit Trail)记录了谁在什么时间修改了哪条数据——这层数据是判断数据可靠性的关键,但大多数人完全不知道它的存在。
把这四类数据拼成一张可以分析的宽表,本身就是一项系统工程。
理解临床数据,绕不开一个名字:CDISC(临床数据交换标准协会)。
它定义了从数据采集到分析的全套语言规范,核心是三层标准的递进结构:
 CDISC SDTM将临床数据切分为多个"域"(Domain),DM是人口统计、LB是实验室数据、AE是不良事件、VS是生命体征……每个域是一个独立的结构化数据集。来源:Certara
CDISC SDTM将临床数据切分为多个"域"(Domain),DM是人口统计、LB是实验室数据、AE是不良事件、VS是生命体征……每个域是一个独立的结构化数据集。来源:Certara
CDASH 规范了EDC系统里字段的命名方式——所以你看到 LBTEST(检验项目名称)和 LBSTRESN(标准结果数值)这样的列名,这就是CDASH的"方言"。
SDTM 把采集来的原始数据整理成标准化的"数据域"表格,每行一条观测记录,行列密集但信息完整。
ADaM 是SDTM的下游,把数据进一步加工成"分析就绪"的宽表——这才是统计师真正跑模型用的格式。
FDA和NMPA的申报文件都要求按CDISC标准提交数据。理解这套结构,不是为了让你成为数据管理员,而是让你能读懂自己数据的"说明书"。
拿到数据之后,很多人的本能反应是打开SPSS或R,直接开始跑分析。 这是一个危险的习惯。
没做过探索性数据分析(EDA)就启动统计检验,就像不看血常规直接开方——你不知道你的假设建立在什么样的地基上。
正确的第一步是数据侦察:这份数据有多少变量?连续变量的分布是否正常?缺失率是多少?有没有明显的录入错误和异常值?不同数据来源之间的受试者ID能对上吗?
传统方式是打开Excel,逐列检查,一个个绘图——一份100个变量的数据集,这个过程可能需要大半天。
这正是 AI Agent 能大幅提效的地方。
最直接的路径是ChatGPT代码解释器(Advanced Data Analysis):上传你的数据文件(CSV或Excel),输入以下Prompt,AI会自动编写并执行Python代码,生成完整的数据探索报告:
你是一名临床数据管理专家。请对我上传的临床试验数据集进行完整的探索性分析,包括:
1. 数据集基本信息(行列数、变量类型分布)
2. 每个变量的缺失率,并标注缺失率>20%的高风险变量
3. 连续变量的分布特征(均值、中位数、四分位数、是否疑似正态)
4. 分类变量的频次统计,标注样本量极少的类别
5. 数值型变量的异常值检测(IQR法),列出疑似异常的记录
6. 生成缺失值热图,直观展示数据质量全貌
输出一份结构化的数据质量报告,用中文描述主要发现。
AI会在几分钟内返回一份带图表的完整报告——缺失值热图、各变量分布直方图、异常值列表,以及用中文写成的数据质量摘要。这件事过去需要统计师花半天完成,现在是一次对话的事。
如果你想走更自动化的路线,PandasAI 允许你用自然语言直接"问"数据:
from pandasai import SmartDataframe import pandas as pd df = SmartDataframe(pd.read_csv("clinical_data.csv")) df.chat("这份数据里缺失最严重的变量是哪些?帮我画出缺失率柱状图。") df.chat("年龄变量有没有明显异常值?")
不需要写Pandas代码,直接用中文提问,AI自动执行并返回结果。
对于更复杂的场景——比如需要同时处理EDC数据、实验室数据、SAE数据三张表的合并与质量检查——可以用Claude或ChatGPT的多步Agent模式,把数据清洗、字段映射、异常检测设计成一条自动化流水线,每一步的执行日志都会留下来,方便溯源和复查。
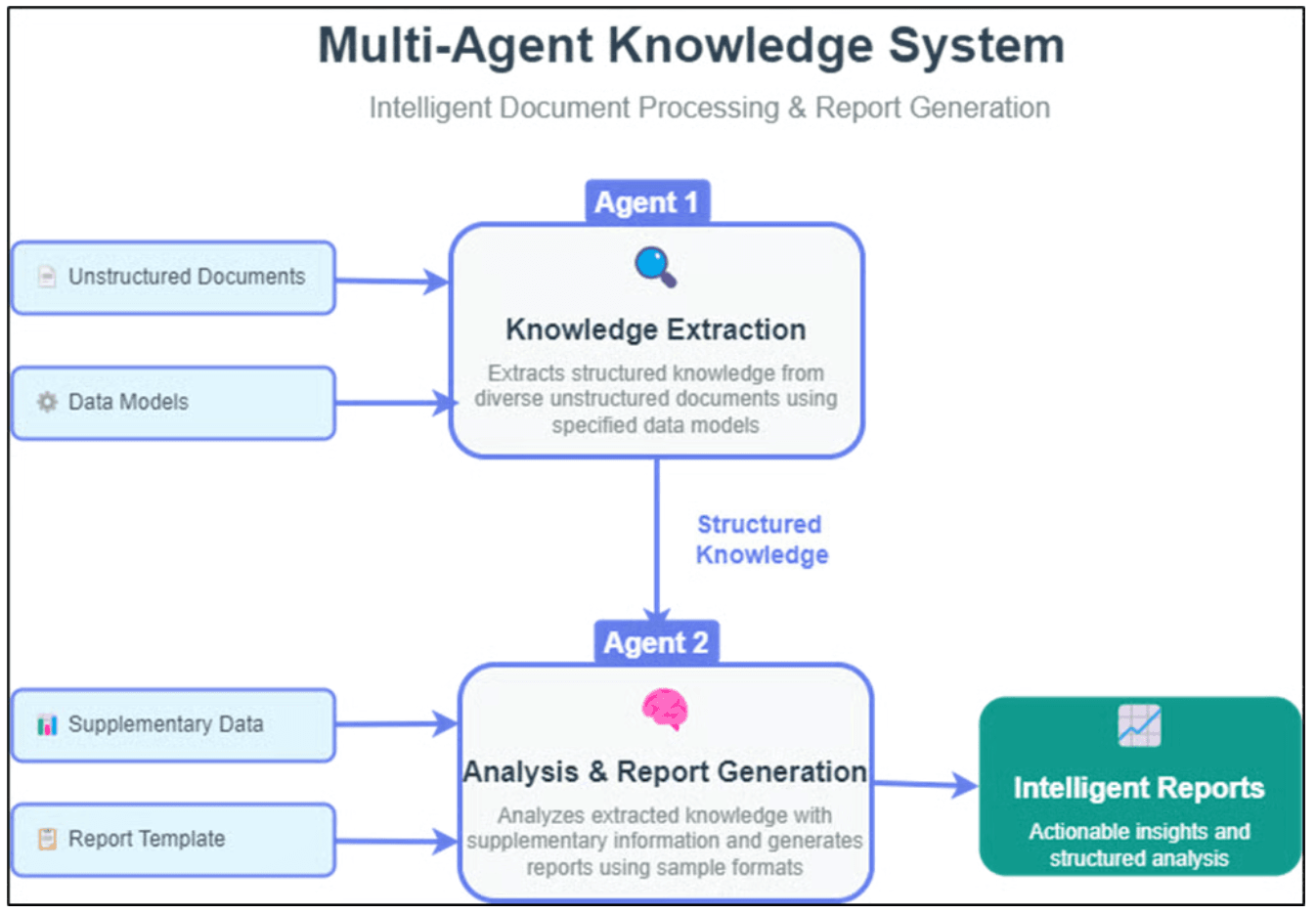
多Agent工作流可以把数据合并、质量检查、异常标记等多个步骤串联成一条自动化流水线,无需人工逐步干预。来源:Medium
AI生成数据质量报告之后,你需要人工判断三件事:
缺失率决定了你后续能用什么统计方法。缺失率低于5%,通常影响不大;5%~20%需要考虑缺失机制;超过20%的变量,在分析前必须做专门处理,不能就这么扔进模型里。(缺失数据的处理,是这个系列第06篇的主题。)
分布形态决定了你用均值还是中位数,用t检验还是非参数检验。一眼看到右偏的实验室值分布,你就知道这个变量在基线表里该汇报中位数(四分位数间距),而不是均值(标准差)。
异常值不等于错误值——老年患者的极端检验值可能是真实的病理状态,也可能是录入失误。AI能帮你列出疑似异常的记录,但去判断"这条数据是真实的还是录错的",必须回到原始病历或CRF,这一步不能交给机器。
数据的结构和质量,是所有统计分析结论可靠性的前提。理解数据的"体型",不是一项技术活,而是每个做临床研究的人应该具备的基本判断力。AI Agent可以把探索过程大幅自动化,但读懂结果、做出判断,始终是你的工作。
下一篇,我们沿着这条数据链路继续往下走:一条临床观测数据从EDC录入,到最终进入分析表,中间到底经历了什么,每一步又藏着哪些改变数据面目的风险。
本系列下一篇: 《从EDC到分析表:一条数据的奇幻漂流》