

开题/综述最烦的不是“找不到论文”,而是这三件事同时发生: 你用中文写了一个很清晰的问题,但检索结果要么很散、要么跑题;你不断改关键词,结果越改越焦虑;最后真正耗掉你的,是筛无关、去重复、补漏网这一整套返工流程。
最近我们开发的 Suppr 超能文献 给了一个新选项:专家模式。它的定位很直白——“卷”文献检索的准确率!
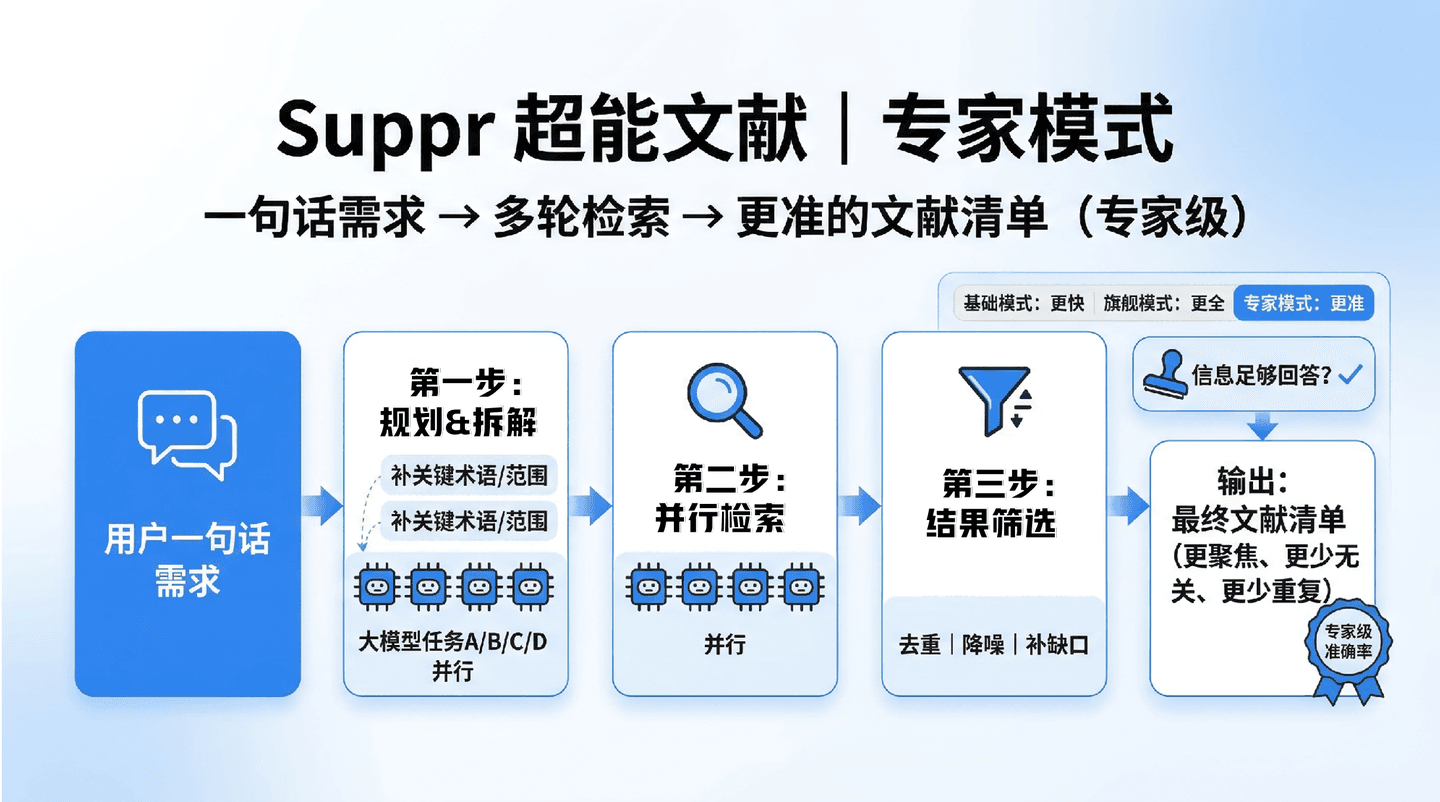
用户一句话需求 → 第1轮/第2轮/第3轮(规划n方向→并行检索→合并去重)→ 判断信息是否足够回答 → 输出最终文献清单
每一轮里不是一个模型单线程搜,而是多个大模型任务并行(可以理解成:有人专门补关键词/同义词,有人专门追指南/RCT,有人专门补亚组/结局/时间窗……)。你可以把它理解为:用更多 token(更多计算)去换更高准确率——这也是它能做到“更准”的原因之一。下面这张图就是面向宣传的通俗版机制示意:
开题和综述常见的真实痛点是:
你以为你在“搜文献”,其实你在做四份工作: 1)把自然语言问题翻译成检索策略; 2)不断修正检索范围; 3)筛噪音、去重复; 4)发现漏网之鱼后再补检索。
专家模式把这四件事尽量自动化:多轮推进负责“不断补缺口”,并行大模型任务负责“同时从多个方向找证据”,最后再合并去重降噪,你拿到的是更聚焦的清单,更接近“导师/师兄师姐会让你先读的那几类关键文献”。它在界面里的表达也很清楚:基础更快、旗舰更全、专家更准(“专家级准确率”)。
然后选 专家模式,让它先跑一轮“定边界 + 补术语”。
综述真正要命的是漏掉关键指南、关键RCT、或一个大家都在引用的“关键节点论文”。专家模式的“多轮+并行”更像是: 第一轮先找最相关的核心集合;第二轮开始追“关键研究类型/关键结局/关键分支”;第三轮再把“亚组、时间窗、替代终点”补齐——最后合并输出。你拿到的是更像“可用的文献池”,而不是一堆需要你从头清洗的数据。图里对这个过程的表达非常直观:多轮卡片 + 并行任务 + 合并去重 + 最终清单。
这意味着用户不需要先付费“赌准不准”,而是可以把最难的一条开题/综述检索丢进去,先体验“准确率提升”带来的节省时间。
如果你最近正在开题/写综述:别先把自己困在关键词里。去 Suppr 超能文献用一句中文把需求写清楚,选「专家模式」,让它用多轮检索 + 多个大模型并行先帮你把“该读的关键文献池”收敛出来——你再去精读和写作,会轻松很多。