

AI破壁·科研小白的临床数据分析实战指南 第01篇
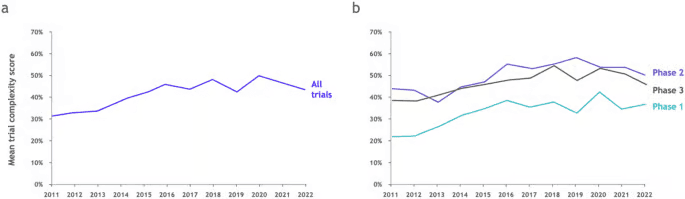
过去十年,I/II/III 期临床试验的复杂度评分全线上升,统计分析要求随之水涨船高。 来源:Nature Scientific Reports, 2024
一位做心血管研究的主治医师曾跟我说过这么一句话:"我读了三遍《医学统计学》,每次读到第三章假设检验就放弃了。后来我花了一万二找了个统计公司,他们给我跑了个SPSS结果,我看都看不懂,只能原样贴进论文。"
这段话里有两层失败:第一层,他没学会统计;第二层,他花了钱,但依然不理解自己的研究结论是怎么来的。
这不是个例。在中国的临床研究生态里,这几乎是一种结构性困境。
临床医生学统计,通常有三条路:一是翻教材,公式推导密密麻麻,看到方差分析的F值就放弃;二是去参加培训班,两天速成课把所有方法走马观花过一遍,回去之后什么都记不住;三是外包给统计师,自己彻底退出数据分析的环节,沦为"数据提供者"。
这三条路的共同问题是:没有人告诉你统计究竟在解决什么问题。
它不是在教你算数,它是在教你如何面对不确定性做出有依据的判断——而这件事,你作为一个每天在临床上做决策的医生,其实天生就懂。
你在评估一个新的降压方案时,你会问:这个效果是真实的,还是这批病人碰巧基线就好?这两组之间的差异,是药的作用,还是运气?你在用临床直觉做的事,和t检验在做的事,是同一件事。只不过统计把它变成了可以量化、可以被审稿人验证的语言。
这个认知上的转变,是学好统计的真正起点。但99%的统计教材都不从这里讲起。
在没有AI之前,"理解统计概念"这件事,高度依赖于你能不能找到一个愿意用人话解释的老师。教材里的定义永远是循环的——用统计学术语解释另一个统计学术语,越看越懵。
ChatGPT和Claude出现之后,这个局面被打破了。
不是因为AI会替你做分析,而是因为AI可以用你能理解的语言,把任何一个让你卡壳的概念解释清楚——而且它会结合你的具体场景,无限次地重新解释,直到你真正理解为止。
这件事的价值远比表面看起来大。理解是执行的前提,不理解统计方法就去用它,是临床研究里最常见的错误来源之一。
下面是一个可以直接复用的Prompt模板,适用于任何你在文献或分析过程中遇到的统计术语:
请你帮我解释"[统计术语]"的含义。 要求: 用临床研究的真实场景举例,不要用纯数学语言; 用临床研究的真实场景举例,不要用纯数学语言; 解释它在解决什么问题、为什么需要它; 告诉我最常见的误解是什么; 最后用一句话给我一个可以记住的"锚点定义"。 场景背景:我是一名[科室/专业]医生,正在做关于[研究方向]的临床研究。
以"置信区间"为例,用这个模板问AI,你会得到的不是"总体参数以某概率落在的区间"这种绕圈子的答案,而是类似这样的解释:
"你做了一个试验,发现新药把收缩压平均降低了8 mmHg,95%置信区间是3到13 mmHg。这意味着:如果你把这个试验重复100次,大概有95次,真实的降压效果会落在这个范围里。它不是说'真实值有95%的概率在这个区间',而是说'这套方法的可靠性是95%'。你应该关注的是区间的宽度——越宽,你的数据越稀疏,结论越不确定。"
这个解释里有场景、有数字、有反直觉的纠正,有可以记住的落脚点。如果你还没理解,可以继续追问。这是教材永远给不了你的东西。
认知重建之后,还需要一整套工具链来支撑实际的分析工作。从数据清洗、基线表生成,到生存分析、回归建模,再到SAP写作、论文发表——每一个环节都有具体的AI提效方案,也都有必须人工把关的边界。
这个系列接下来的19篇文章,会沿着一条真实的临床研究工作流,把这些场景一个个拆开来讲。不是教你"用AI偷懒",是让你真正理解自己在做什么,然后把重复的、机械的部分交给工具,把判断和理解留给自己。
统计自主权,是每一个做临床研究的人都应该拥有的能力。现在,你有了更好的工具去拿到它。
本系列下一篇: 《你的临床数据,到底长什么样——让AI帮你做第一次"体检"》